Server-Side Tracking Without Cookies In Go
Published on 22. June 2020
I was looking for an alternative to Google Analytics to track visitors on a website. Analytics (and most of its competitors) provide detailed information and real-time data at the cost of privacy. Google can track you across sites using a bunch of different techniques and through their Chrome browser. Combined, this can be assembled to a detailed profile that can not only be used for tracking, but for marketing too.
I found some (open source) alternatives like GoatCounter, which anonymously collect data without invading the user's privacy. But all of the tools I found either rely on cookies, which the visitor needs to opt-in for or cost money for the server-side only tracking solution. While I'm willing to pay for good software, especially when it comes from a small team or just one developer, I was wondering if I could build something that I can integrate into my Go applications.
This post is about my solution called Pirsch, an open-source Go library that can be integrated into your applications to tracks visitors on the server-side, without setting cookies. I will write about the technique used and what the advantages and disadvantages are.
TL;DR
Invading the privacy of your website visitors is evil. Pirsch is a privacy-focused tracking library for Go that can be integrated into your applications. Check it out on GitHub!
You can find a live demo here on my website and the whole thing on GitHub as a sample application.
What's With the Name?
Pirsch is German and refers to a special kind of hunt: the hunter carefully and quietly enters the area to be hunted, he stalks against the wind in order to get as close as possible to the prey without being noticed.
I found this quite fitting for a tracking library that cannot be blocked by the visitor. Even though it sounds a little sneaky. Here is the Gopher for it created by Daniel.

How Does It Work?
I will go over each step in more detail later, but here is a high-level overview of how Pirsch tracks visitors.

Once someone visits your website, the HTTP handler calls Pirsch to store a new hit and goes on with whatever it intends to do. Pirsch will do its best to filter out bots, calculate a fingerprint, and stores the page hit. You can analyze the data and generate statistics from it later.
The process must be triggered manually by calling the Hit method and passing the http.Request. This enables you to decide which traffic is tracked and which is not. I'm usually just interested in page visits, so I'll add a call to Pirsch inside my page handlers. Resources are served on a different endpoint and won't be tracked that way.
Fingerprinting
Fingerprinting is a technique to identify individual devices by combing some parameters. The parameters are typically things like the graphics card ID and other variables that are unique to a device. As we are interested in tracking website traffic, we won't have access to this kind of information. Instead, we can make use of the IP and HTTP protocol. Here are the parameters used by Pirsch to generate a fingerprint:
-
the IP is the most obvious choice. It might change, as ISPs only have a limited pool of IPs available to them, but that shouldn't happen too frequently
-
the User-Agent HTTP header contains information about the browser and device used by the visitor. It might not be filled though, but it usually is
To generate a unique fingerprint from this information, we can calculate a hash. Pirsch will add the current day to prevent tracking users across days and calculate an MD5 hash. I found this to be the fastest algorithm available in the Go standard library. This will also make the visitor anonymous at the same time as we do not store IPs or other identifiable information.
This method is called passive fingerprinting, as we're only using data that we have access to anyways. The alternative is called active fingerprinting, which makes use of JavaScript to collect additional information on the client-side and sends it to the backend. But as we're trying to build a privacy-focus tracking solution, passive fingerprinting is the way to go.
We will use the fingerprint later to count unique visitors.
Filtering Bots
Filtering out bot traffic is hard, as there is no complete list of all bots and they won't send any special kind of information, like an I'm a bot header. All we can do is to process the IP and the User-Agent header send and make some assumptions. Pirsch will look for terms often used by bots within the User-Agent header. Should it contain words like bot or crawler or an URL, the hit will be dropped. Filtering for IP ranges is not implemented (yet), but you can filter hits that are coming from popular IP ranges, like AWS.
Hits
Each page request is stored as a Hit. A hit is a data point that can later be analyzed. Here is the definition of a hit:
// I removed some details to make it more readable for this blog post
type Hit struct {
Fingerprint string
Path string
URL string
Language string
UserAgent string
Ref string
Time time.Time
}
A hit contains the full request URL, the path extracted from the URL, the language, user-agent and reference passed by the client in their corresponding headers and the time the request was made.
Analyze
Pirsch provides an Analyzer that can be used to extract some basic statistics:
-
total visitor count
-
visitors by page on each day
-
visitors by hour on each day
-
languages used by visitors
-
active visitors within a time frame
Most of these functions accept a filter to specify a time frame. The data can then be plotted like on my tracking page.
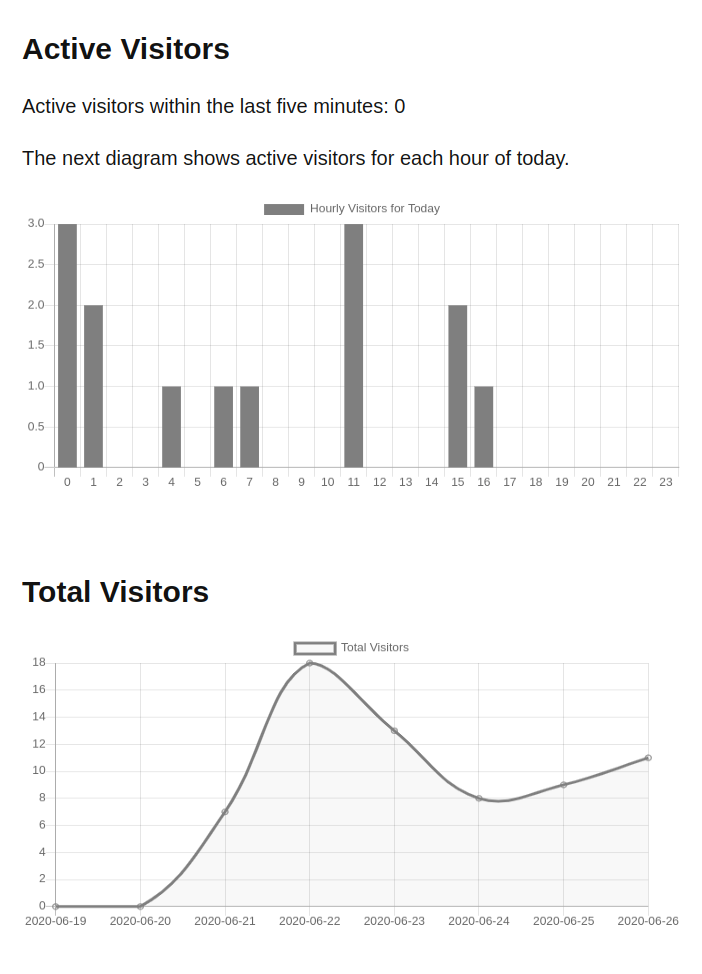
To reduce the amount of data that needs to be processed the hits get aggregated each night and hits are cleaned up afterward.
Postgres is used as the storage backend at the moment as it is a fantastic open-source database and provides all features needed to read these statistics easily. You can extract more statistics, like the visitor page flow, from the database if you care.
Tracking From JavaScript
While it is simple to integrate tracking into your backend, you might also want to have some way to track from your frontend as well, in case you're running a single page application for example. In that case, you can add an endpoint to your router and call it using Ajax. The path can manually be overwritten in Pirsch by calling HitPage instead of Hit.
How Well Does It Work?
As far as I can tell right now, it works pretty well. I still need to collect more sample data and a way to compare it to something like Google Analytics in order to make a more precise statement. Keep in mind that while Analytics and other tools provide more detailed statistics, like the location, age, gender, and so on, they can be blocked by tools like uBlock. Pirsch cannot be blocked by the client and therefore it can track visitors you won't even notice with a client-side solution.
Bots are probably the weak spot of Pirsch right now, as filtering for them requires adding a whole bunch of keywords to the filter list.
Another disadvantage of server-side tracking depending on your use-case might be that you cannot track your marketing campaigns. In case you're using Adsense for marketing, you can track how well your campaigns perform through Analytics. This won't work with Pirsch.
Conclusion
Tracking on the server-side isn't too hard to archive and all in all, I think it's worth the effort. I hope you gained some insight into how you can use fingerprinting and Pirsch to your advantage. I will continue improving Pirsch and implement it into Emvi and compare the output to Analytics. I might also add a user interface for Pirsch so that you can host it without integrating it into your application and without the need to generate the charts yourself. In case you would like to send me feedback, have a question, or would like to contribute you can contact me.